Enabling highly available global anycast DNS modifications with Galera
Last time, we set up a global anycast PowerDNS cluster with geolocation and health checks. This enables it to provide high availability for other services, always sending the user to a node that’s up.
However, there was one flaw—there is a single master node, which is the single point of failure for writes. When it goes down, it becomes impossible to make changes to the DNS, even though the “slave”1 nodes in the anycast will continue to serve the zone, including performing availability checks.
Last time, I also hinted at MariaDB Galera clusters becoming
important. This time, we’ll leverage Galera, a multi-master solution for
MariaDB, to eliminate the dependency on the single master. We’ll also make
poweradmin highly available so that we can edit DNS records through a nice UI,
instead of running API requests through curl or executing SQL queries
directly.
Without further ado, let’s dive in.
Table of contents
- Motivation
- What is Galera?
- Choosing a topology
- Converting to a Galera cluster
- Making the slave nodes select an available master
- Deploying additional poweradmin instances
- High availability for poweradmin
- Conclusion
Motivation
The master PowerDNS node going down wasn’t just a theoretical problem. I was inspired to eliminate that single point of failure because of something that actually happened a few weeks ago.
As it happened, the datacentre my master node was in suffered a failure with their cooling system, resulting in the following intake temperature graph for my server:
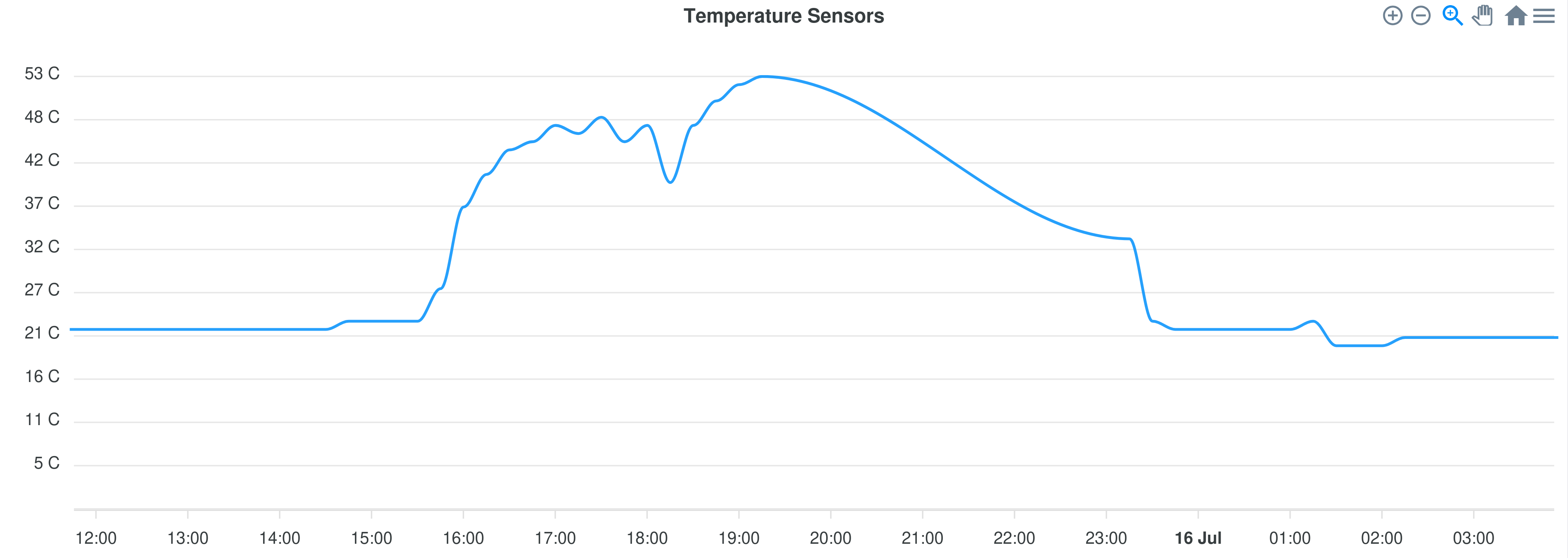
I can’t imagine it was very comfortable inside the datacentre at 53 °C, and a lot of networking equipment inside agreed, shutting down to prevent damage. This brought my server down, including the PowerDNS master running in a VM. After this incident, I decided to make the master node highly available.
What is Galera?
Galera is a multi-master solution for MariaDB. Every node in a Galera cluster
can be written to, and the data has to be replicated to a majority of nodes in
the cluster before the write is deemed successful. Galera requires at least 3
nodes, with an odd number of nodes being preferred to avoid split-brain
situations, which can happen after a network partition and prevent the cluster
from figuring out which side of the partition has the majority and can continue
serving writes. A lightweight node can be run with Galera Arbitrator
(garbd), which participates in consensus decisions but doesn’t have a
copy of the database. Therefore, the minimum Galera cluster is two database
servers and one garbd.
Also note that only the InnoDB storage engine is supported with Galera. It’s the default engine, and there’s very little reason to use any other engine with MariaDB unless you are doing something really special.
It is possible to mix Galera and standard replication, of which we made heavy use last time, such as by having replication slaves replicate from Galera cluster nodes.
Choosing a topology
My first idea was to use a Galera cluster involving every node, replacing standard replication. This resulted in a Galera cluster with 10+ nodes spread around the globe. Due to network reliability issues with transcontinental links, the Galera cluster regularly disconnects and has to resync, resulting in transactions sometimes taking over a minute to commit.
That was definitely a bad idea, but it proved that using standard replication is the right choice for cross-continental replication.
Therefore, I instead chose to deploy three Galera nodes, one in Kansas City, one in Toronto, and another in Montréal. At these distances, Galera performs perfectly fine for occasional DNS updates. The result is something like this, with red indicating the changes from last time:

Note that with three nodes, the cluster can only tolerate a single node failing. It would no longer allow any writes when two nodes fail, as the remaining node would no longer be part of a majority to establish consensus. So naturally, you want your Galera nodes to be in separate locations to avoid a single event, such as a natural disaster or a regional power outage, disrupting multiple nodes simultaneously.
The slave nodes will continue to use standard replication, replicating from any available master. This is not possible with the default MariaDB setup, but I found a solution for it anyway, which we’ll discuss later.
Converting the master node to a Galera cluster
We assume that we spin up two additional masters, at 192.0.2.2 and
192.0.2.3, respectively. Remember, you need at least three nodes in a Galera
cluster, at least two of which must be MariaDB. We will use three MariaDB nodes.
Using garbd is left as an exercise for the reader.
Converting the master node to Galera was surprisingly simple. All I had to do
was insert a bunch of lines into /etc/mysql/mariadb.conf.d/71-galera.conf,
which should be created on every Galera node:
[mariadbd]
# Turns on Galera
wsrep_on = 1
# You may need to change the .so path based on your operating system
wsrep_provider = /usr/lib/libgalera_smm.so
# You might want to change this cluster name
wsrep_cluster_name = example-cluster
wsrep_slave_threads = 8
# List out all the nodes in the cluster, including the current one.
# Galera is smart enough to filter that one out, so you can just keep this file
# in sync on all masters.
wsrep_cluster_address = gcomm://192.0.2.1,192.0.2.2,192.0.2.3
wsrep_sst_method = mariabackup
wsrep_sst_auth = mysql:
# Some tuning to tolerate higher latencies, since we aren't replicating in the same datacentre
wsrep_provider_options = 'gcs.max_packet_size=1048576; evs.send_window=512; evs.user_send_window=512; gcs.fc_limit=40; gcs.fc_factor=0.8'
# Required MariaDB settings
binlog_format = row
default_storage_engine = InnoDB
innodb_autoinc_lock_mode = 2
# Galera replication
wsrep_gtid_mode = ON
wsrep_gtid_domain_id = 0
log_slave_updates = ON
log_bin = powerdns
# You want the same server_id on all Galera nodes, as they effectively function
# as one for the purposes of standard replication.
server_id = 1
# Enable writes
read_only = 0
Most of /etc/mysql/mariadb.conf.d/72-master.conf has been made redundant. Only
bind_address should be kept. You should define bind_address on all Galera
nodes so that they can be replicated from.
For good measure, you should add a unique value for gtid_domain_id on each
server, master or slave, Galera or not, in either 72-master.conf or
72-slave.conf, that differs from wsrep_gtid_domain_id and each other, though
this is not strictly necessary if all writes happen with Galera.
Note that for wsrep_sst_method = mariabackup to function, mariadb-backup
needs to be able to authenticate when executed by the mariadbd process running
under the mysql user. Instead of using a password, we can use unix_socket
authentication, which requires the 'mysql'@'localhost' user to be created and
granted certain permissions. Run the following command in sudo mariadb on your
existing master to create the user:
CREATE USER 'mysql'@'localhost' IDENTIFIED VIA unix_socket;
GRANT RELOAD, PROCESS, LOCK TABLES, BINLOG MONITOR ON *.* TO 'mysql'@'localhost';
If you are using a firewall, you’ll need to allow TCP ports 4567 (for regular Galera communications), 4568 (for incremental state transfers), and 4444 (for regular state transfers) between Galera nodes.2
Now, we are ready to restart the MariaDB master in Galera mode:
sudo systemctl stop mariadb.service
sudo galera_new_cluster
On the new masters, simply restarting MariaDB will cause it to join the Galera cluster:
sudo systemctl restart mariadb.service
Note that this will destroy all data currently on those servers, so back those up if you have anything important.
You can run sudo mariadb on any Galera master and run SHOW STATUS LIKE
'wsrep_cluster_%'; to see the status. You should see wsrep_cluster_size=3 (or
however many nodes you actually have) and wsrep_cluster_status=Primary. This
means the cluster is alive and ready for operation.
You should probably also set up some sort of monitoring for this, such as using
mysqld-exporter and Prometheus, or perhaps use
the wsrep_notify_cmd script, but doing any of this is left as an exercise for
the reader.
If it didn’t work, check sudo journalctl -u mariadb.service for errors.
Making the slave nodes select an available master
We note that CHANGE MASTER TO can only set one MASTER_HOST, which means if
we pointed it at any given Galera node, replication will stop if that master
node dies. Since the cluster can still be updated by the other masters, this
will cause stale data to be served, which is not ideal.
I first thought about using something like haproxy or nginx stream proxy, which can connect to a different node when connection to the upstream fails, and make the slave replicate from that. However, I quickly realized that MariaDB MaxScale is a much better solution. It supports several forms of high availability for MariaDB, such as failing over standard replication that we talked about last time. However, it can also proxy to arbitrary Galera nodes, with awareness of Galera state, so that it can always route the request to a member of the cluster that’s functional.
While MaxScale is a paid product and each release is licensed under a proprietary licence called BSL, three years after the initial release, the release branch reverts to GPLv2 or newer. This means that at the time of writing, MaxScale 21.06 has reverted to GPL and can be freely used without restrictions, while still receiving patches. Since we don’t really need any newer features, this suits us just fine.
So we need to install MaxScale 21.06 on every slave. You can use MariaDB’s repository setup script, or just run the following commands:
curl -o /etc/apt/keyrings/mariadb-keyring-2019.gpg https://supplychain.mariadb.com/mariadb-keyring-2019.gpg
cat > /etc/apt/sources.list.d/maxscale.sources <<'EOF'
X-Repolib-Name: MaxScale
Types: deb
URIs: https://dlm.mariadb.com/repo/maxscale/21.06/debian
Suites: bookworm
Components: main
Signed-By: /etc/apt/keyrings/mariadb-keyring-2019.gpg
EOF
apt update
apt install -y maxscale
We then replace /etc/maxscale.cnf on every slave:
[maxscale]
threads=1
skip_name_resolve=true
[galera1]
type=server
address=192.0.2.1
port=3306
[galera2]
type=server
address=192.0.2.2
port=3306
[galera3]
type=server
address=192.0.2.3
port=3306
[galera-monitor]
type=monitor
module=galeramon
servers=galera1,galera2,galera3
user=maxscale_monitor
password=hunter2
monitor_interval=2s
[galera-reader]
type=service
router=readconnroute
servers=galera1,galera2,galera3
router_options=synced
user=maxscale
password=hunger2
[galera-replicator]
type=listener
service=galera-reader
address=127.0.0.1
port=3307
This effectively makes MaxScale listen on 127.0.0.1:3307, which, when
connected to, will route to any available Galera node.
Also note that the communication between MaxScale and MariaDB nodes is unencrypted, so this is only suitable over LAN or VPN. For a direct WAN connection, you should probably set up TLS.
Note that MaxScale requires two users to be created, so let’s create them on the
Galera cluster with sudo mariadb:
-- The user maxscale_monitor is used exclusively to monitor the cluster.
-- Usual quirks regarding host restrictions and passwords apply.
CREATE USER 'maxscale_monitor'@'%' IDENTIFIED BY 'hunter2';
GRANT SLAVE MONITOR ON *.* TO 'maxscale_monitor'@'%';
-- The user maxscale is required for MaxScale to read system tables and
-- authenticate clients.
-- Usual quirks regarding host restrictions and passwords apply.
CREATE USER 'maxscale'@'%' IDENTIFIED BY 'hunter2';
GRANT SELECT ON mysql.user TO 'maxscale'@'%';
GRANT SELECT ON mysql.db TO 'maxscale'@'%';
GRANT SELECT ON mysql.tables_priv TO 'maxscale'@'%';
GRANT SELECT ON mysql.columns_priv TO 'maxscale'@'%';
GRANT SELECT ON mysql.procs_priv TO 'maxscale'@'%';
GRANT SELECT ON mysql.proxies_priv TO 'maxscale'@'%';
GRANT SELECT ON mysql.roles_mapping TO 'maxscale'@'%';
GRANT SHOW DATABASES ON *.* TO 'maxscale'@'%';
Now, restart MaxScale on every slave node with sudo systemctl restart
maxscale.service. Then, repeat the slave provisioning process, but instead run
this CHANGE MASTER command:
CHANGE MASTER TO
MASTER_HOST="127.0.0.1",
MASTER_PORT=3307,
MASTER_USER="replication",
MASTER_PASSWORD="hunter2",
MASTER_USE_GTID=slave_pos;
There’s probably a way to avoid rebuilding the entire slave, but given that I have scripts to provision them, I just reprovisioned. Doing it without a full reprovisioning is left as an exercise for the reader.
Either way, once you START SLAVE;, you should check SHOW SLAVE STATUS\G and
verify that replication is working. If it is, great!
I am also quite impressed by MaxScale’s memory efficiency, using around 15 MiB of memory at startup, and that goes down to around 2-3 MiB when just holding a connection open. It’s basically a drop in the bucket for this replication setup.
Deploying additional poweradmin instances
Now, having the Galera cluster isn’t super helpful when the master node with the PowerDNS API and poweradmin goes down, as you have no way of modifying DNS records short of running direct queries against the surviving masters. This is why you need to deploy PowerDNS and poweradmin on all masters.
In both cases, the state is stored in the database, so simply duplicating all
the configuration files and running them on each master will work. For
poweradmin, this means copying /srv/poweradmin/inc/config.inc.php instead of
rerunning the installer.
However, there’s a slight problem: poweradmin uses PHP sessions, which by default are stored on disk. This means that when you hit a different node, you are logged out—clearly not ideal.
I implemented a database-powered backend for PHP sessions3, which you can
store as /srv/poweradmin/inc/pdo_sessions.php:
<?php
class PDOBackedSession implements SessionHandlerInterface {
public function __construct($dsn, $user = null, $pass = null, $options = []) {
$this->dsn = $dsn;
$this->user = $user;
$this->pass = $pass;
$this->options = array_merge([
PDO::ATTR_ERRMODE => PDO::ERRMODE_EXCEPTION,
], $options);
}
public function register() {
session_set_save_handler($this, true);
}
public function open($path, $name) {
try {
$this->pdo = new PDO($this->dsn, $this->user, $this->pass, $this->options);
return true;
} catch (PDOException $e) {
return false;
}
}
public function close() {
$this->pdo = null;
return true;
}
public function read($sid) {
$stmt = $this->pdo->prepare('SELECT data FROM php_sessions WHERE id = ?');
$stmt->execute([$sid]);
$result = $stmt->fetch(PDO::FETCH_ASSOC);
return $result ? $result['data'] : '';
}
public function write($sid, $data) {
$stmt = $this->pdo->prepare('REPLACE INTO php_sessions VALUES (?, ?, ?)');
$stmt->execute([$sid, time(), $data]);
return true;
}
public function destroy($sid) {
$stmt = $this->pdo->prepare('DELETE FROM php_sessions WHERE id = ?');
$stmt->execute([$sid]);
return true;
}
public function gc($lifetime) {
$stmt = $this->pdo->prepare('DELETE FROM php_sessions WHERE access < ?');
$stmt->execute([time() - $lifetime]);
return true;
}
}
While this class is intended to be extensible to support non-MySQL/MariaDB databases, I don’t have the energy to implement it. Contributions are welcome. It’s currently available as a gist, so check there for an updated version if one becomes available.
You will need to run sudo mariadb powerdns on a Galera node and create this
table:
CREATE TABLE php_sessions (
id VARCHAR(32) NOT NULL PRIMARY KEY,
access BIGINT NOT NULL,
data BLOB NOT NULL
);
Then, you’ll need to patch /srv/poweradmin/index.php:
--- a/index.php
+++ b/index.php
@@ -39,6 +39,9 @@ session_set_cookie_params([
'httponly' => true,
]);
+include __DIR__ . '/inc/pdo_sessions.php';
+include_once __DIR__ . '/inc/config.inc.php';
+(new PDOBackedSession($db_type . ':host=' . $db_host . ';dbname=' . $db_name, $db_user, $db_pass))->register();
session_start();
$router = new BasicRouter($_REQUEST);
Now, poweradmin should be storing PHP sessions in the database.
High availability for poweradmin
Now we just need a way to always send users to an available instance of
poweradmin. We can, of course, just use PowerDNS Lua records for this. Assuming
you are running example.com with the PowerDNS cluster, you would need to move
poweradmin to poweradmin.example.com.
We’ll assume that the public IPv4 addresses for the master nodes are
198.51.100.1, 198.51.100.2, 198.51.100.3 and the IPv6 addresses are
2001:db8::1, 2001:db8::2, 2001:db8::3.
Then, simply create the following records:
poweradmin.example.com. 300 IN LUA A "ifurlup('https://poweradmin.example.com/index.php?page=login', { {'198.51.100.1', '198.51.100.2', '198.51.100.3'} }, {stringmatch='Please provide a username', selector='pickclosest'})"
poweradmin.example.com. 300 IN LUA AAAA "ifurlup('https://poweradmin.example.com/index.php?page=login', { {'2001:db8::1', '2001:db8::2', '2001:db8::3'} }, {stringmatch='Please provide a username', selector='pickclosest'})"
Updating the nginx configuration is left as an exercise for the reader.
Now, poweradmin.example.com should automatically point to the nearest
available instance of poweradmin, and each instance of poweradmin connects to
the local Galera node. DNS updates are possible even if a single node fails. In
fact, you won’t even be logged out of poweradmin!
You can also do something similar for the PowerDNS API if you have scripts that rely on it, but that’s also left as an exercise for the reader.
Conclusion
Last time, we successfully constructed a highly available PowerDNS cluster with availability checks and geolocation to steer users towards nearby available instances of services, enabling high availability. This time, we leveraged it—along with Galera—to deploy a highly available application: poweradmin, which is used to manage this cluster.
I hope this demonstrates the power of this approach to high availability. Similar concepts can be applied to most other web applications, although a new mechanism becomes necessary if applications depend on storing data as files instead of a database.
In either case, I hope you found this post useful. See you next time!
Notes
-
For various reasons, people have been trying to replace the terms used for the different node types in replication. For simplicity and to reduce confusion, we are going to stick with the traditional terminology since they are the only ones that work in every context with MariaDB.
The newer terms are inconsistently applied at the time of writing, with the MariaDB documentation freely mixing different terminology, making it hard to understand and harder to know which commands to use. Even worse, the new commands they introduced are also internally inconsistent, leading to confusing situations like the following interaction, which doesn’t happen with the old commands:
MariaDB [(none)]> SHOW REPLICA STATUS\G *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event ...Needless to say, this should not be construed as any endorsement of the practice of enslaving humans. ↩
-
If you are using multicast, you may also need UDP port 4567. However, setting up multicast is left as an exercise for the reader. ↩
-
I hate PHP. The language is super unintuitive, a naming convention is non-existent, and the documentation is horrible. You know something is wrong when you have to rely on corrections in the comments on the docs to successfully code a simple class. ↩